


Table of contents
🗂️ Hive SerDe
SerDe is short for Serializer/Deserializer. Hive uses the SerDe
interface for IO. The interface handles both serialization and
deserialization and also interpreting the results of serialization
as individual fields for processing.
A SerDe allows Hive to read in data from a table, and write it
back out to HDFS in any custom format. Anyone can write their
own SerDe for their own data formats
Serialization
Process of converting an object in memory into bytes that can be stored in a file or transmitted over a network
Deserialization
Process of converting the bytes back into an object in memory
Built-in SerDes
- Avro
- ORC
- RegEx
- Thrift
- Parquet
- CSV
- JsonSerDe
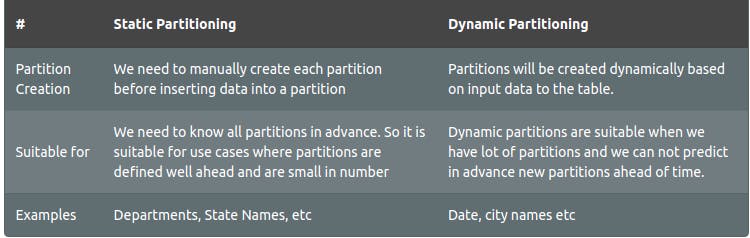
📝 Hive Partitions
Static Partition
In Static Partitioning, we have to manually decide how many partitions tables will have and also value for those partitions
Dynamic Partition
Dynamic partitions provide us with flexibility and create partitions automatically depending on the data that we are inserting into the table
✅ Hive Sort by vs Order by
Sort by
- Uses multiple reducers to produce final output
- It Only guarantees ordering of rows within a reducer
Order by
- Uses only single reducer to produce final output
- LIMIT can be used to minimize sort time