


What is Hive ?
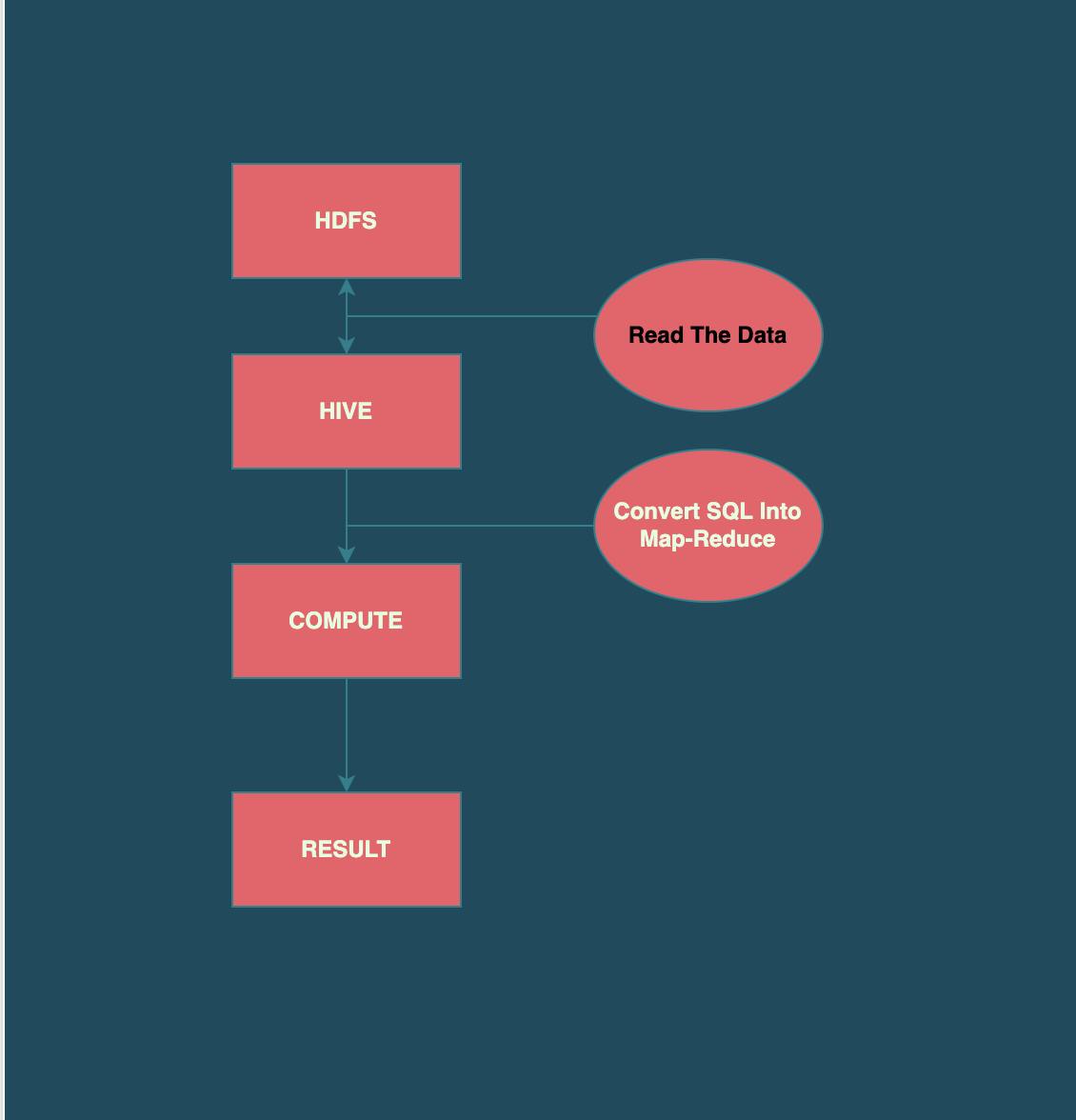
Hive is built on top of Apache Hadoop, which is an open-source framework used to efficiently store and process large datasets. As a result, Hive is closely integrated with Hadoop, and is designed to work quickly on petabytes of data. What makes Hive unique is the ability to query large datasets, leveraging MapReduce, with a SQL-like interface
Hive Architecture
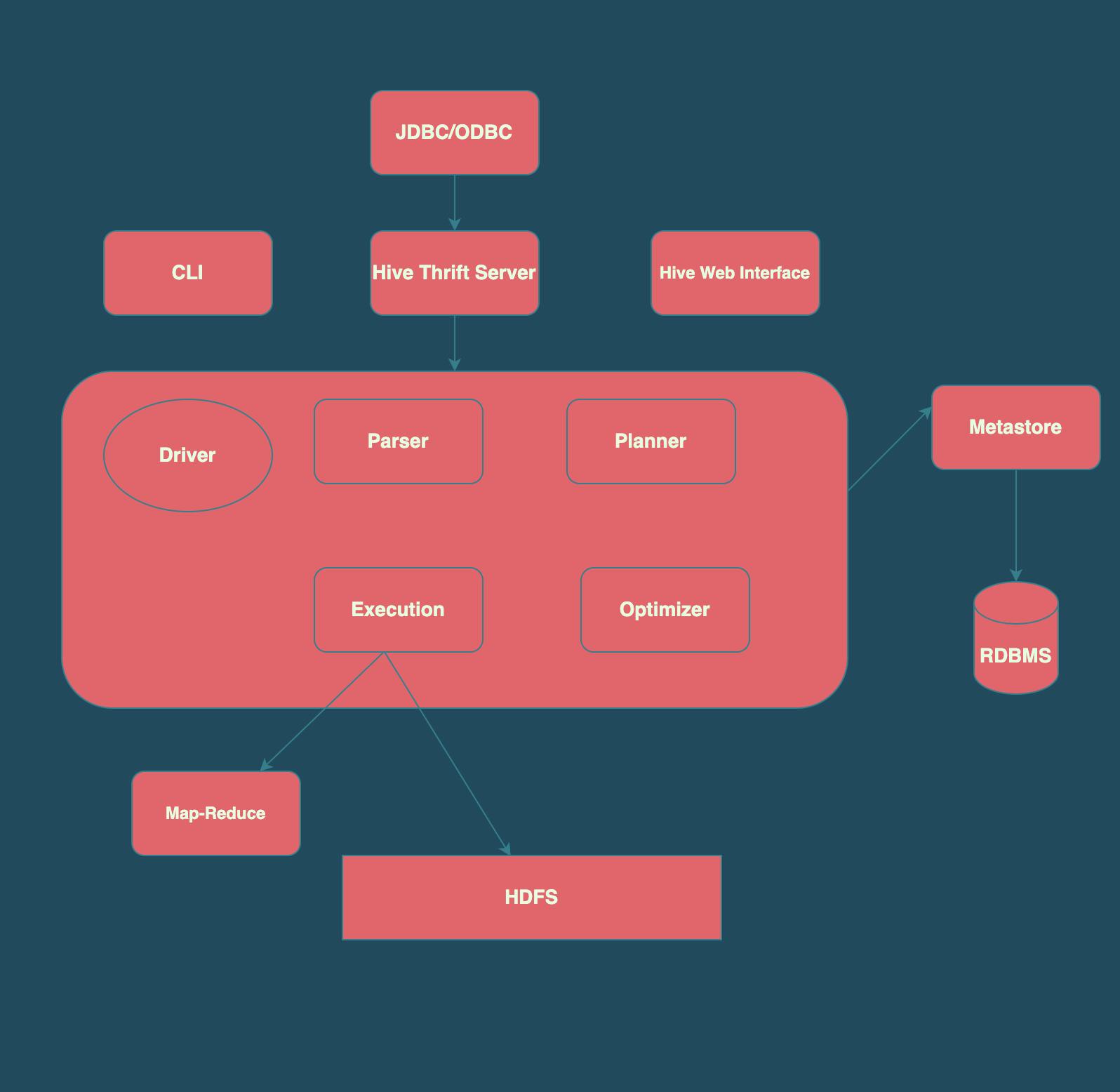
Hive Client
JDBC client
A JDBC driver connects to Hive using the Thrift framework. Hive Server communicates with the Java applications using the JDBC driver
ODBC client
The Hive ODBC driver uses Thrift to connect to Hive. However, the ODBC driver uses the Hive Server to communicate with it instead of the Hive Server
Thrift Clients
The Hive server can handle requests from a client by using Apache Thrift
CLI
The Hive CLI (Command Line Interface) is a shell where we can execute Hive queries and commands
Hive Web Interface
The Hive Web UI is just an alternative of Hive CLI. It provides a web-based GUI for executing Hive queries and commands
Driver
- Controller for HQL statements
- Creates session for query
- Maintains lifecycle of HQL
- Maintains metadata for execution
- Collects output and display
Parsing / Compilation
- Syntex check
- Execution plan
- Prepare different steps to get an output
- Raise compile time errors
Optimizer
- Compares execution plans
- Calculate cost
- Execution plan of DAG
- Try to place or combine transformations together
Execution
Optimizer generates the logical plan in the form of DAG of map-reduce tasks and HDFS tasks. In the end, the execution engine executes the tasks
Metastore
Metastore stores metadata information about tables and partitions, including column and column type information, in order to improve search engine indexing.
Two types
| Internal Databases (Derby Database) | External Database |
| Can't have metadata backup | Provides metadata backup |
| Only one connection at a time | More multiple connnection |
| Only for internal use cases | Expose to external use cases |
Benefits of using Hive
- Simple to use
- Built on top of hadoop
- Typical SQL kind of framework
- Logic will be converted into map-reduce code